精度无损,成本减半!KunLun AI Space基于昇腾实现DeepSeek V3.1 FP8原生推理
在科技飞速发展的当下,AI领域的每一次突破都备受瞩目。最近,DeepSeek V3.1的发布,犹如一颗投入平静湖面的石子,在业界激起层层涟漪,尤其是其中的UE8M0 FP8,更是成为了众人热议的焦点。
为何FP8能成为大模型的“新宠”?相较于传统的 FP16/BF16精度,FP8能将显存需求直接减半,大幅缓解硬件资源压力;而对比INT8(W8A8)精度,FP8的推理精度更高、表示范围更广,完美平衡了“效率”与“精度”。然而,长期以来,FP8精度的原生支持高度依赖海外芯片,严重制约了相关技术的自主发展与广泛应用。
在此背景下,河南昆仑技术有限公司(简称:昆仑技术)基于昇腾灵活易用的Ascend C算子开发框架,成功研发出软FP8解决方案,为大模型部署构建起更经济、更自主的技术路径,更让昇腾平台具备了快速兼容后续新出FP8权重格式模型的能力,进一步丰富了昇腾AI生态的应用版图。
具体来看,该方案通过定制化Ascend C算子实现核心突破:一方面,将FP8权重模型输入昇腾硬件,通过精准的反量化算子,转化为BF16格式参与计算,既保障了计算过程的准确性,又为后续新FP8权重模型的快速适配预留了灵活空间,无需权重格式的多次转换;另一方面,带来了显著的应用价值——在模型精度几乎无损的前提下,单台KunLun G8600即可流畅运行满血版DeepSeek V3.1模型;即便在KunLun G5500V2、KunLun G5580等标卡机型上,也能实现模型参数规模翻番,同时大幅提升并发处理能力,让不同硬件配置的用户都能享受到FP8推理的技术红利。
三大技术优势,筑牢高效推理根基
算子级创新:自研FP8反量化算子,显存与内存带宽双减半
● 深度定制,创新突破:首创Kernel内动态反量化方案,自主研发高性能FP8 Matmul / GroupedMatmul算子,计算精度与原生浮点无差异。
● 混合精度,精准高效:通过混合精度计算策略,在保证算子精度的同时,大幅降低Vector核计算负载,实现性能与精度的双重优化。
● 流水优化,充分压榨:将Vector与Cube两部分算子进行融合,高效调度两类核上的计算任务,通过调优矩阵分块策略、数据预取机制等手段,彻底消除计算流水线气泡,充分释放硬件潜能。
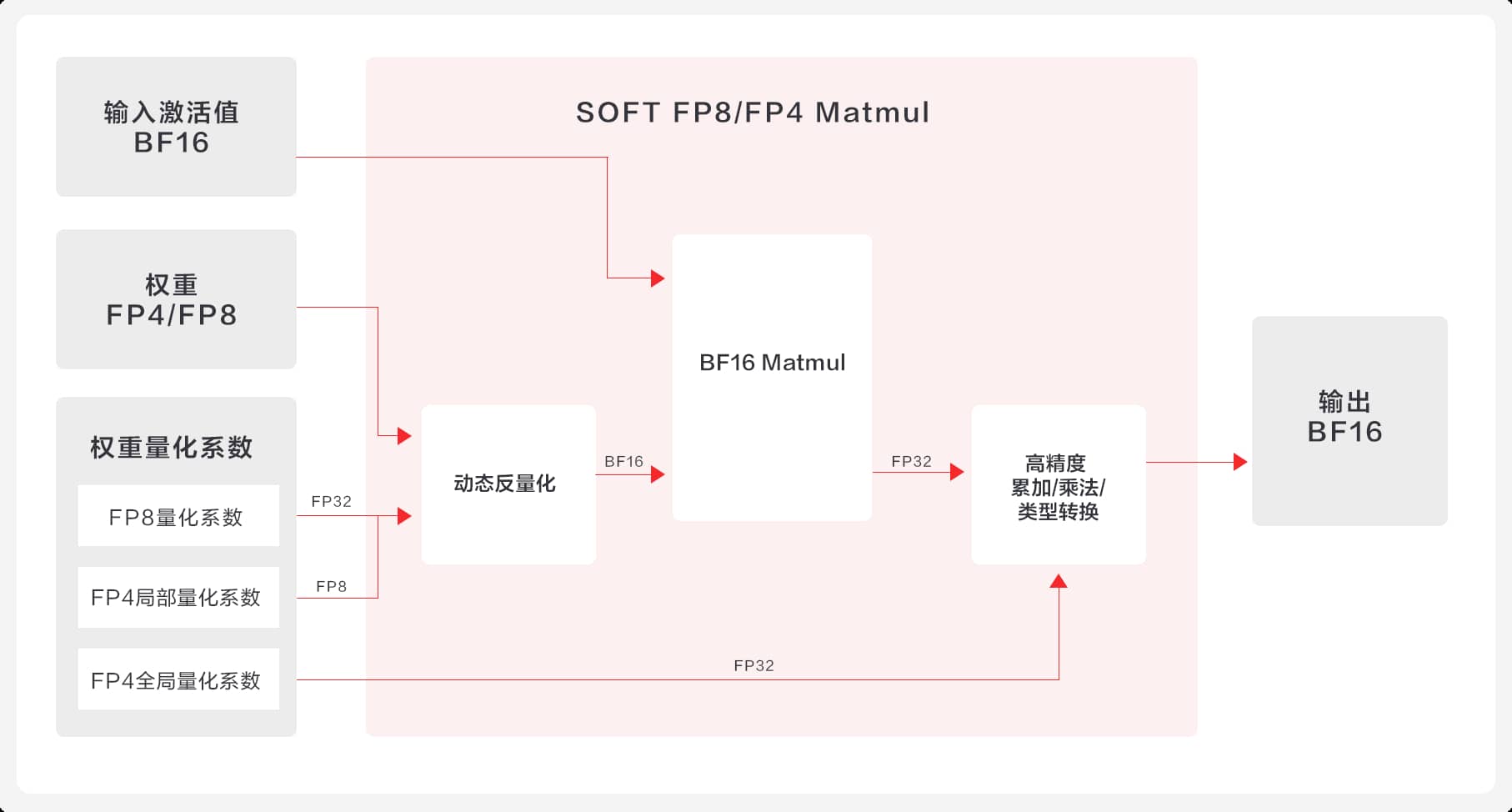 SOFT FP8/FP4 Matmul算子实现方案原理图
SOFT FP8/FP4 Matmul算子实现方案原理图
框架级加速:算子整图下发,推理效率飙升32%
整图下发,效率提升:通过PyTorch的Meta函数注册实现,使得自研FP8反量化算子整体入图下发,避免了单个算子依次下发带来的性能开销;同时,利用模型特征的智能感知,实现计算路径的动态调整,端到端推理效率再提升32%。
生态级兼容:主流模型无缝支持
KunLun AI Space软FP8解决方案全面兼容DeepSeek V3.1、DeepSeek-V3/R1、Qwen3等主流FP8量化模型,为用户提供灵活多样的模型选择。同时,该方案具备很好的扩展性,可以快速支持后续新出的模型。
在FP8低精度类型已成为大模型主流选择的当下,KunLun AI Space凭借自研软FP8解决方案,在精度和性能几乎无损的情况下,大幅降低了大模型部署的算力门槛和成本,为大模型私有化部署提供了更加可行的方案。
与此同时,昆仑技术的探索脚步并未就此停歇。目前,软FP4的方案已经在紧锣密鼓地研发当中,预计不久后就将与大家见面。展望未来,KunLun AI Space将持续深入挖掘昇腾芯片的算力潜力,推动大模型私有化部署从“可用”走向“普惠”。